RandomForest ist ein Classifier Algorithmus
Theoretische Funktionsweise
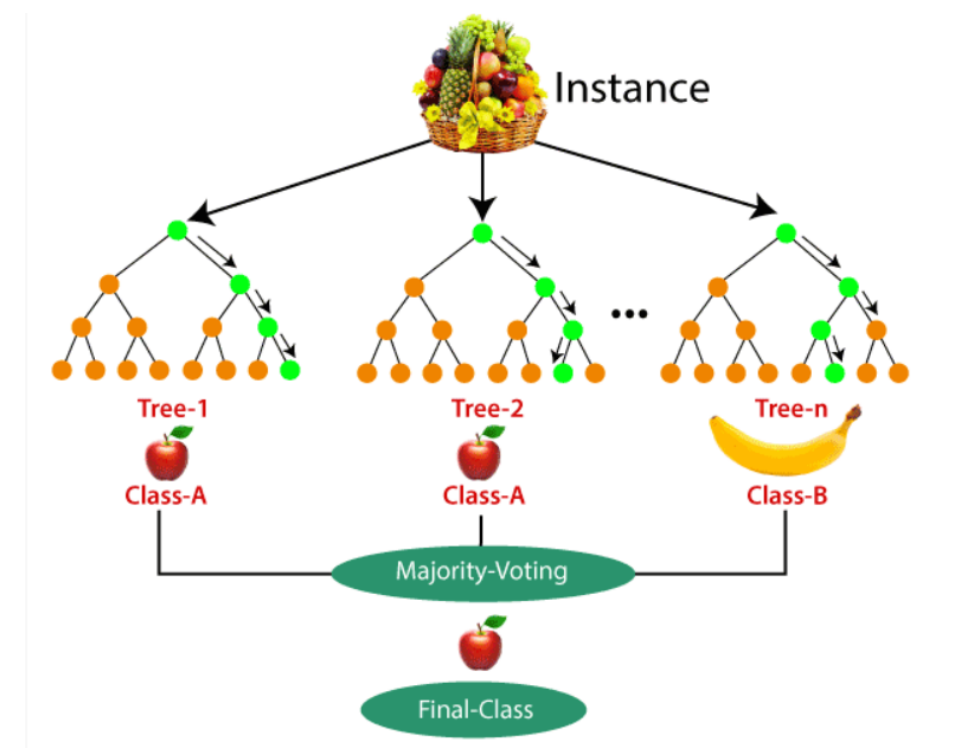
Beim Random Forest kombiniert man mehrere Entscheidungsbäume (Decision Trees) zu einem Forest. Dabei wird das Ergebnis aller einzelner Bäume zuletzt verglichen und ein Mehrheitsentscheid gebildet.
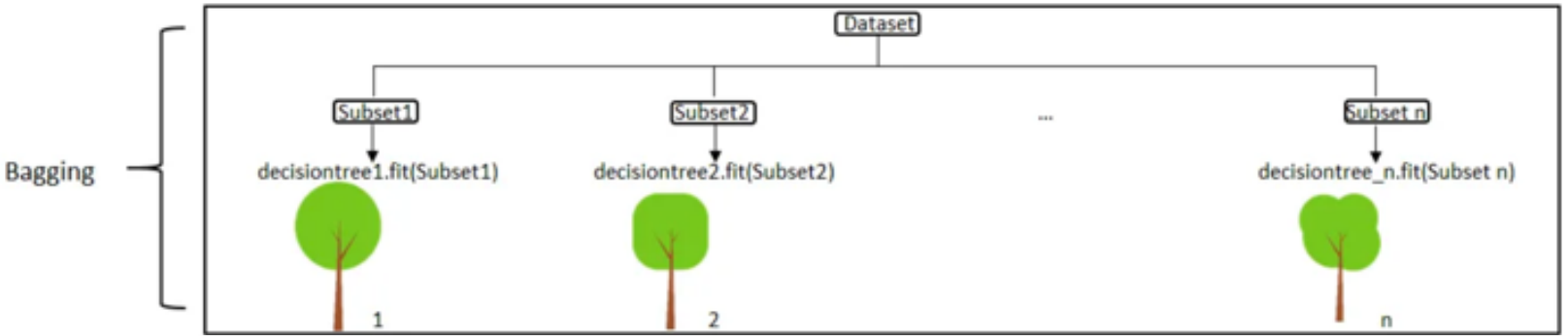
Bagging
Bootstrap Aggregating bedeutet, dass jeder Baum mit einem zufälligen Teil des Trainingsdatasets trainiert wird.
Das bedeutet, dass ein Teil der Trainingsdaten wieder (mehrfach) für ein Training verwendet wird. Dieses Mehrfach verwenden nennt man Training “mit Ersatz”
Ingesamt verwendet jeder Baum ca. 65% des Datasets.
Beispiel:
Dataset: (A, B, C, D)
Ziehung 1: A
Ziehung 2: C
Ziehung 3: A
Ziehung 4: B
Über den Parameter bootstrap=False kann dies deaktiviert werden.
Programmierung
Import
from sklearn.ensemble import RandomForestClassifierErstellen eines RandomForest Objekts
RandomForestClassifier(
n_estimators: Int = 100,
*=100,
criterion: Literal['gini', 'entropy', 'log_loss'] = "gini",
max_depth: Int | None = None,
min_samples_split: float = 2,
min_samples_leaf: float = 1,
min_weight_fraction_leaf: Float = 0,
max_features: float | Literal['sqrt', 'log2'] = "sqrt",
max_leaf_nodes: Int | None = None,
min_impurity_decrease: Float = 0,
bootstrap: bool = True,
oob_score: bool = False,
n_jobs: Int | None = None,
random_state: Int | RandomState | None = None,
verbose: Int = 0,
warm_start: bool = False,
class_weight: Mapping[Unknown, Unknown] | Sequence[Mapping[Unknown, Unknown]] |
Literal['balanced', 'balanced_subsample'] | None = None,
ccp_alpha: float = 0,
max_samples: float | None = None
)Parameter
| Parameter | Bedeutung | Mögliche Werte |
|---|---|---|
n_estimators | die Anzahl der Bäume | number |
bootstrap | Bagging ein- bzw. ausschalten | boolean |
criterion | Kriterium anhand dem entschieden wird wie die Qualität der Spaltung ist gini: die Wahrscheinlichkeit das die Klassifikation falsch ist entropy: misst die Unordnung bzw. Unsicherheit der Übrigen Daten | "gini" / "entropy" / "log_loss" |
max_depth | die maximale Tiefe (wie viele Datenknoten max. gebildet werden sollen) | number |
min_samples_leaf | wie viele Datenpunke nach einer Teilung noch vorhanden sein müssen | number |
min_samples_split | wie viele Datenpunke vor der Teilung vorhanden sein müssen | number |
max_features | die Anzahl an Features (Merkmalen) die zum aufteilen berücksicht werden sollen | sqrt / log2 |
| Beispiel: |
clf = RandomForestClassifier(
criterion="gini", max_depth=4, min_samples_leaf=2, max_features="log2"
)Trainieren des Classifiers
clf.fit(x_train, y_train)Bewerten der Genauigkeit
accuracy = clf.score(x_test, y_test)Einen neuen Punkt klassifizieren
y_pred = clf.predict(x_test)