DecisionTree ist ein Classifier Algorithmus
Theoretische Funktionsweise
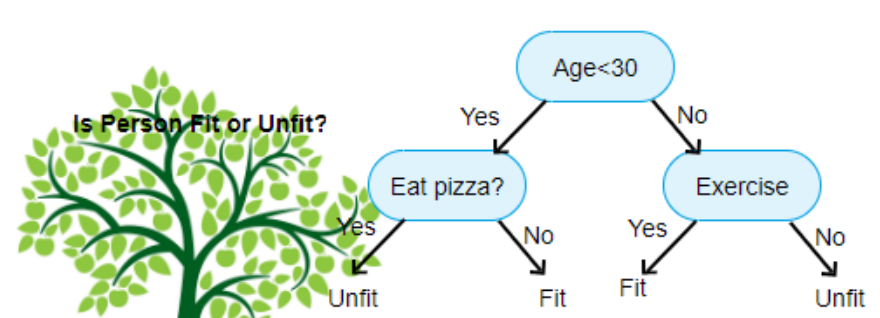
Ein Entscheidungsbaum bzw. Decision Tree hat einen baumähnlichen Aufbau. Dieser wird verwendet, um Entscheidungsstufen und mögliche Antwortpfade darzustellen. Ein Entscheidungsbaum besteht aus einer Wurzel, Ästen, Knoten und Blättern. Die Wurzel stellt dabei den Ausgangspunkt der Entscheidungen, während die Äste die verschiedenen Entscheidungsmöglichkeiten repräsentieren und die Knoten die Zwischenschritte darstellen. Als Blätter bezeichnet man die unterste Ebene eines Entscheidungsbaums.
Programmierung
Import
from sklearn.tree import DecisionTreeClassifierErstellen eines DecisionTree Objekts
DecisionTreeClassifier(
criterion: Literal['gini', 'entropy', 'log_loss'] = "gini",
splitter: Literal['best', 'random'] = "best",
max_depth: Int | None = None,
min_samples_split: float = 2,
min_samples_leaf: float = 1,
min_weight_fraction_leaf: Float = 0,
max_features: float | Literal['auto', 'sqrt', 'log2'] | None = None,
random_state: Int | RandomState | None = None,
max_leaf_nodes: Int | None = None,
min_impurity_decrease: Float = 0,
class_weight: Mapping[Unknown, Unknown] | str | Sequence[Mapping[Unknown, Unknown]]
| None = None,
ccp_alpha: float = 0
)Beispiel:
clf = DecisionTreeClassifier(
criterion="gini", max_depth=4, min_samples_leaf=2, max_features="log2"
)Parameter
| Parameter | Bedeutung | Mögliche Werte |
|---|---|---|
criterion | Kriterium anhand dem entschieden wird wie die Qualität der Spaltung ist gini: die Wahrscheinlichkeit das die Klassifikation falsch ist entropy: misst die Unordnung bzw. Unsicherheit der Übrigen Daten | "gini" / "entropy" / "log_loss" |
max_depth | die maximale Tiefe (wie viele Datenknoten max. gebildet werden sollen) | number |
min_samples_leaf | wie viele Datenpunke nach einer Teilung noch vorhanden sein müssen | number |
min_samples_split | wie viele Datenpunke vor der Teilung vorhanden sein müssen | number |
max_features | die Anzahl an Features (Merkmalen) die zum aufteilen berücksicht werden sollen | sqrt / log2 |
Trainieren des Classifiers
clf.fit(x_train, y_train)Bewerten der Genauigkeit
accuracy = clf.score(x_test, y_test)
print(f"accuracy: {accuracy*100.0:.4}%")Einen neuen Punkt klassifizieren
y_pred = clf.predict(x_test)Visualisierung
from sklearn.tree import plot_tree
_ = plot_tree(clf)