Der Transformer besteht aus mehreren Transformer Blocks sowie einem LM head.
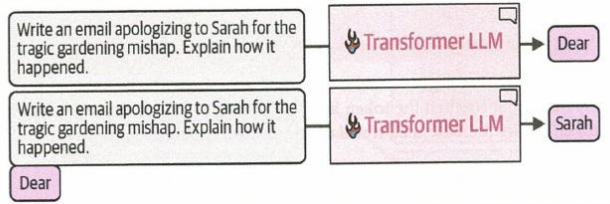
- Der Prompt wird in den Transformator geladen, hier wird das erste/nächste Wort der Ausgabe generiert
- Das generierte wort wird an den Prompt gehängt und wieder dem Transformator übergeben
- Das wiederholt sich bis die Antwort fertig ist der die maximale Token Anzahl erreicht ist
Transformer Block
Ein Transformer Block besteht aus dem Feedforward Layer und dem Self-Attention Layer
Self-Attention Layer
Hier wird der Kontext der Tokens erkannt, z.B. dass sich das “der” in “Der Hund, der bellt.” Auf “Hund” bezieht.
Für Self-Attention werden die Embeddings in 3 neue Embeddings umgewandelt
- Query (Q) – Was suche ich?
- Key (K) – Was biete ich an?
- Value (V) – Welche Information trage ich bei? Sie stellen alle das selbe Token dar und darüber können Gewichtungen einfließen.
Feedforward Layer
Hier passiert der Zugriff auf die gespeicherten Daten. Hier wird der nächste Output Token generiert.