Theoretische Funktionsweise
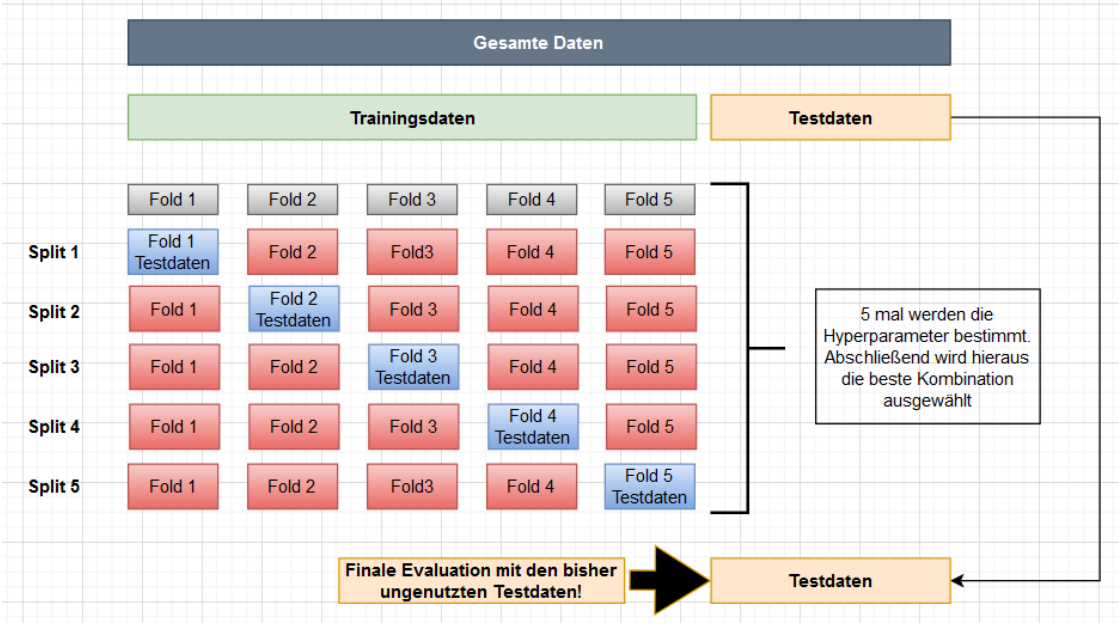
Neben den Hyperparametern spielen die Test- und Trainingsdaten eine erhebliche Rolle bei der Bewertung. Man teilt die Trainingsdaten in k-Bestandteile auf (z.B. k=5 hier Fold). Anschließend werden die k-Modelle (hier Split bzw. Iteration) trainiert. Dabei werden je Modell immer ein Fold als Testdaten benutzt. Abschließend ergibt sich für jedes dieser Modelle (Iteration) ein Score. Zuletzt bildet man den Mittelwert über alle Scores und erhält somit eine aussagekräftige Größe.
GridSearch
Bei Grid Search erstellt man methodisch mehrere Modelle (wie ein Gitter) und wertet anschließend den Score aus. Anschließend wählt man das beste Modell und trainiert dies mit den Trainingsdaten. Abschließend erfolgt die Auswertung über den Score mit Hilfe der Testdaten. Beispiel: Bei KNN kann man hier über verschachtelte for-Schleifen verschiedene k-Werte in Kombination mit der Gewichtung (weights) distance oder uniform testen.
RandomSearch
Bei Random Search werden zufällig verschiedene Modelle erstellt und anschließend der Score bewertet. Das beste Modell wird danach wieder mit den Trainingsdaten trainiert und mit den Testdaten der Score bestimmt. Beispiel: Bei KNN würde man nicht alle Kombinationen aus einem Intervall von 1 bis 100 testen, sondern beispielsweise nur 20, diese jedoch auch nicht mit allen Kombinationen aus distance und uniform.
Programmieren
Import
from sklearn.model_selection import cross_val_scoreBerechnen des Scores
cross_val_score(
estimator: BaseEstimator,
X: MatrixLike,
y: MatrixLike | ArrayLike | None = None,
*,
groups: ArrayLike | None = None,
scoring: str | ((...) -> Unknown) | None = None,
cv: int | BaseCrossValidator | Iterable[Unknown] | None = None,
n_jobs: Int | None = None,
verbose: Int = 0,
fit_params: dict[Unknown, Unknown] | None = None,
pre_dispatch: Int | str = "2*n_jobs",
error_score: Float | str = ...
)Beispiel:
scores = cross_val_score(clf, x_train, y_train, cv=10)Parameter
- estimator : estimator object implementing ‘fit’
- The object to use to fit the data.
- X : {array-like, sparse matrix} of shape (n_samples, n_features)
- The data to fit. Can be for example a list, or an array.
- y : array-like of shape (n_samples,) or (n_samples, n_outputs), default=None
- The target variable to try to predict in the case of supervised learning.
- groups : array-like of shape (n_samples,), default=None
- Group labels for the samples used while splitting the dataset into train/test set. Only used in conjunction with a “Group”
cvinstance (e.g.,GroupKFold).
- Group labels for the samples used while splitting the dataset into train/test set. Only used in conjunction with a “Group”
- scoring : str or callable, default=None
- Strategy to evaluate the performance of the
estimatoracross cross-validation splits. - str: see
scoring_string_namesfor options. - callable: a scorer callable object (e.g., function) with signature
scorer(estimator, X, y), which should return only a single value. Seescoring_callablefor details. None: theestimator’sdefault evaluation criterion <scoring_api_overview>is used.- Similar to the use of
scoringincross_validatebut only a single metric is permitted.
- Strategy to evaluate the performance of the
- cv : int, cross-validation generator or an iterable, default=None
- Determines the cross-validation splitting strategy. Possible inputs for cv are:
None, to use the default 5-fold cross validation,- int, to specify the number of folds in a
(Stratified)KFold, CV splitter,- An iterable that generates (train, test) splits as arrays of indices.
- For
int/Noneinputs, if the estimator is a classifier andyis either binary or multiclass,StratifiedKFoldis used. In all other cases,KFoldis used. These splitters are instantiated withshuffle=Falseso the splits will be the same across calls. - Refer
User Guide <cross_validation>for the various cross-validation strategies that can be used here.
- Determines the cross-validation splitting strategy. Possible inputs for cv are:
- n_jobs : int, default=None
- Number of jobs to run in parallel. Training the estimator and computing the score are parallelized over the cross-validation splits.
Nonemeans 1 unless in ajoblib.parallel_backendcontext.-1means using all processors. SeeGlossary <n_jobs>for more details.
- Number of jobs to run in parallel. Training the estimator and computing the score are parallelized over the cross-validation splits.
- verbose : int, default=0
- The verbosity level.
- params : dict, default=None
- Parameters to pass to the underlying estimator’s
fit, the scorer, and the CV splitter.
- Parameters to pass to the underlying estimator’s
- pre_dispatch : int or str, default=‘2*n_jobs’
- Controls the number of jobs that get dispatched during parallel execution. Reducing this number can be useful to avoid an explosion of memory consumption when more jobs get dispatched than CPUs can process. This parameter can be:
None, in which case all the jobs are immediately created and spawned. Use this for lightweight and fast-running jobs, to avoid delays due to on-demand spawning of the jobs- An int, giving the exact number of total jobs that are spawned
- A str, giving an expression as a function of n_jobs, as in ‘2*n_jobs’
- Controls the number of jobs that get dispatched during parallel execution. Reducing this number can be useful to avoid an explosion of memory consumption when more jobs get dispatched than CPUs can process. This parameter can be:
- error_score : ‘raise’ or numeric, default=np.nan
- Value to assign to the score if an error occurs in estimator fitting. If set to ‘raise’, the error is raised. If a numeric value is given, FitFailedWarning is raised.