Import
from sklearn.mixture import GaussianMixtureObjekt erstellen
Clustering Algorithmus erstellen
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=n_clusters, random_state=0, n_init="auto")
kmeans.fit(x)Daten skalieren
from sklearn.preprocessing import StandardScaler
scale=StandardScaler()
scale.fit(X_original)
X=scale.transform(X_original)GMM initialisieren
gmm = GaussianMixture(
n_components=5, # Anzahl der Cluster (Aus Elbow Chart)
means_init=kmeans.cluster_centers_, # Initialisierung der Mittelpunkte
max_iter=100 # Anzahl der durchzuführenden Iterationen
)GMM trainieren
gmm.fit(X) Neuen Punkt vorhersagen
gmm_kmeans_labels = gmm.predict(X) Funktionsweise
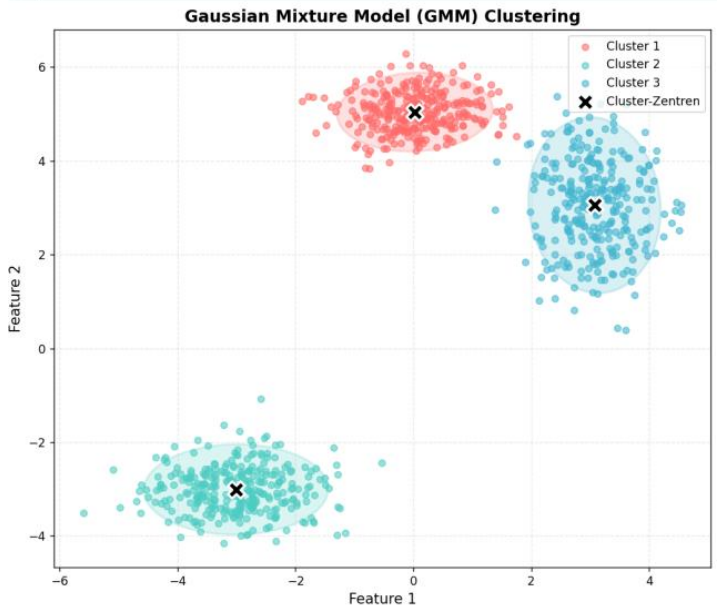
GMM wird verwendet wenn kein
yDataset vorhanden ist. Es kann aus dem Cluster derx-Daten die Klassen ableiten.
Die Mittelpunkte der Klassen werden z.B. mit KMeans berechnet.
GMM geht davon aus dass die Daten der Klassen aus Normalverteilungen bestehen.
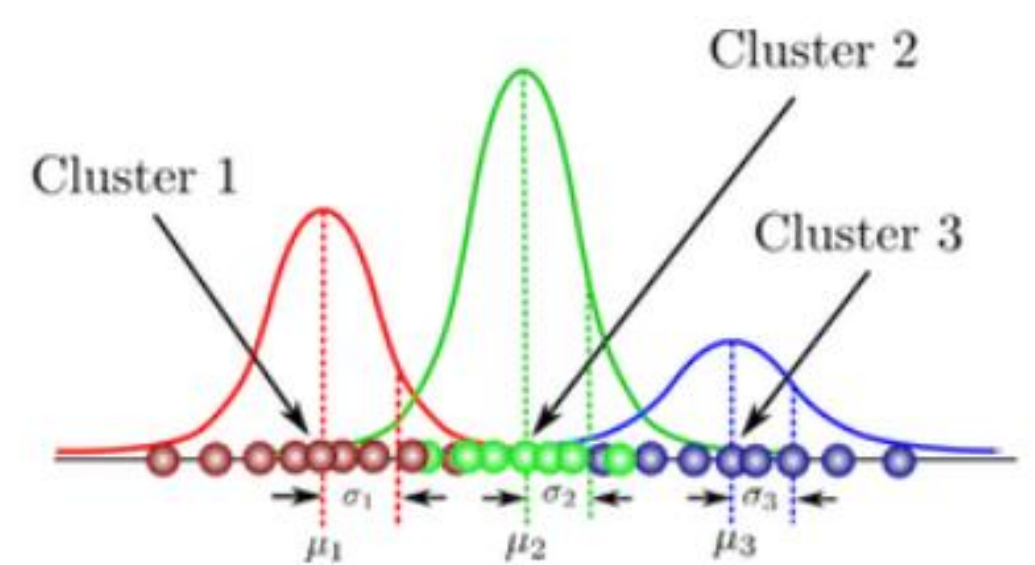
Parameter
- Mittelwert (Mean)
- Der Mittelpunkt des Clusters.
- Kovarianz Matrix (Covariance Matrix)
- Beschreibt die Form und Ausdehnung des Clusters.
- Gewichtung (Weight)
- Gibt an, wie wahrscheinlich es ist, dass ein Punkt zu einem bestimmten Cluster gehört.
Expectation-Maximization Algorithmus (EM)
- E-Schritt (Expectation)
- Berechne die Wahrscheinlichkeit, dass jeder Datenpunkt zu jedem Cluster gehört, basierend auf den aktuellen Parametern.
- M-Schritt (Maximization)
- Aktualisiere die Parameter (Mittelwerte, Kovarianzen und Gewichte) basierend auf den Wahrscheinlichkeiten aus dem E-Schritt.
- Iterieren
- Wiederhole die Schritte E und M, bis die Parameter stabil sind oder eine bestimmte Anzahl von Iterationen erreicht ist