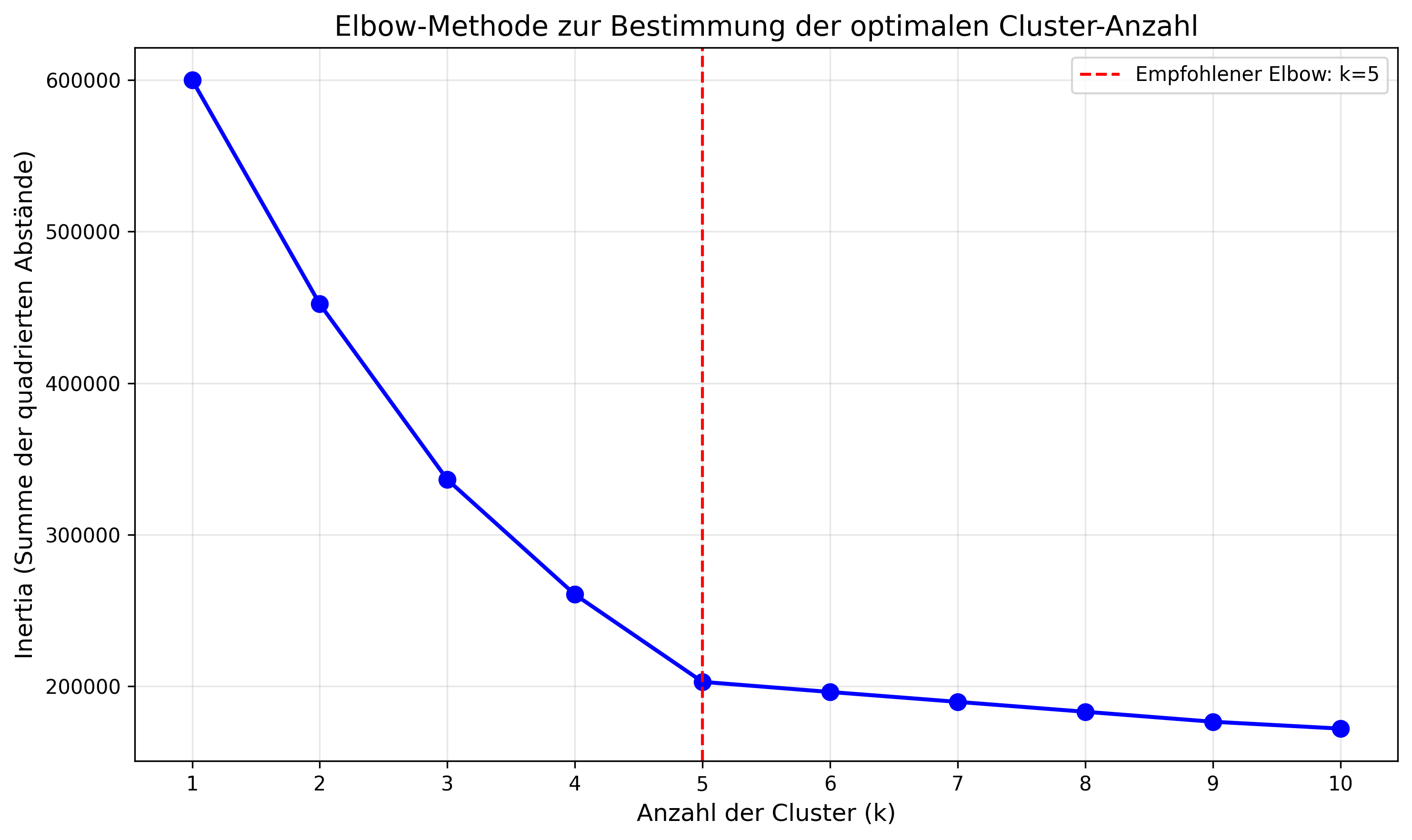
"""Elbow-Methode für K-Means ClusteringErstellt einen Elbow-Chart zur Bestimmung der optimalen Cluster-Anzahl"""import numpy as npimport matplotlib.pyplot as pltfrom sklearn.cluster import KMeansfrom sklearn import datasetsfrom sklearn.preprocessing import StandardScalerdef create_elbow_chart(X, max_clusters=10, random_state=42): """ Erstellt einen Elbow-Chart für K-Means Clustering Parameter: ---------- X : array-like Die Daten für das Clustering max_clusters : int Maximale Anzahl der zu testenden Cluster (Standard: 10) random_state : int Zufallszustand für Reproduzierbarkeit (Standard: 42) Returns: -------- kmeans_estimator : list Liste der KMeans-Modelle für jede Cluster-Anzahl inertias : list Liste der Inertia-Werte für jede Cluster-Anzahl """ # Für bessere Ergebnisse, werden die Daten standardisiert # Die Funktion wird später noch genauer erklärt scaler=StandardScaler() X=scaler.fit_transform(X) inertias = [] K_range = range(1, max_clusters + 1) kmeans_estimator = [] # Berechne Inertia für verschiedene Cluster-Anzahlen for k in K_range: kmeans = KMeans(n_clusters=k, random_state=random_state, n_init=10) kmeans.fit(X) #Bestimmerung der Trägheit (Inertia) #(Summe der quadrierten Abstände zu den nächsten Cluster-Zentren) inertias.append(kmeans.inertia_) kmeans_estimator.append(kmeans) # Erstelle den Elbow-Chart plt.figure(figsize=(10, 6)) plt.plot(K_range, inertias, 'bo-', linewidth=2, markersize=8) plt.xlabel('Anzahl der Cluster (k)', fontsize=12) plt.ylabel('Inertia (Summe der quadrierten Abstände)', fontsize=12) plt.title('Elbow-Methode zur Bestimmung der optimalen Cluster-Anzahl', fontsize=14) plt.grid(True, alpha=0.3) # Ruft die aktuellen Teilstrichpositionen und Beschriftungen der x-Achse ab oder legt sie fest plt.xticks(K_range) # Markiere den "Elbow"-Punkt (vereinfachte Heuristik) if len(inertias) > 2: # Berechne die zweite Ableitung (Krümmung) differences = np.diff(inertias) second_diff = np.diff(differences) # Bestimme den Index des maximalen Krümmungspunkts elbow_point = np.argmax(second_diff) + 2 # +2 wegen zweifachem diff # Markiere den Elbow-Punkt im Diagramm, mit vertikaler Linie plt.axvline(x=elbow_point, color='r', linestyle='--', label=f'Empfohlener Elbow: k={elbow_point}') plt.legend() plt.tight_layout() plt.savefig('elbow_chart.png', dpi=300, bbox_inches='tight') print("Elbow-Chart wurde als 'elbow_chart.png' gespeichert") plt.show() return (kmeans_estimator, inertias)# Beispielaufruf der Funktioncreate_elbow_chart(x_data, max_clusters=5, random_state=33)
Beispiel mit KMeans
# Dataset ladenfrom sklearn import datasetsfrom sklearn.model_selection import train_test_splitwine = datasets.load_wine()X = wine.datax_train, x_test, y_train, y_test = train_test_split(X, wine.target, test_size=0.3)# Beste Clusterzahl mit Elbow_Chartfrom Elbow_Chart_Funktion import create_elbow_chartkmeans_estimator,ineritas = create_elbow_chart(X, 10)# Das optimale KMeans Objekt, Anschließend wird es trainiertclf = kmeans_estimator[2] # Hier 2 weil Elbow 3 angezeigt hatprint("Labels: ", clf.labels_)print("Cluster Centers: ", clf.cluster_centers_)print("Predicted Lables: ", clf.predict(X))# Ein paar Zusatzinformationen auslesenprint(X.shape[1])print(wine.target)