Eigenschaften von Big Data
- Volume: Menge an Daten
- Variety: Vielfalt der Daten
- Velocity: Geschwindigkeit mit der neue Daten generiert und verarbeitet werden
- Veracity: Genauigkeit, Zuverlässigkeit der Daten
Horizontale Skalierung
Bei Big Data (sehr großen und vielen Daten) ist die horizontale Skalierung der Speicherumgebung sehr wichtig.
Horizontal bedeutet das mehrere Server zu einem Cluster zusammen geschlossen werden. Eine solche verteilte Datenbank nennt man auch verteiltes System.
Bei der horizontalen Skalierung im Big Data Umfeld werden (mehrere Gigabyte) große Dateien in kleine Chunks (z. B. 64MB) aufgeteilt und über mehrere Server verteilt.
Jede Datei wird auch öfters (z. B. 3 mal) auf einem Cluster gespeichert, damit auf diese trotz Ausfall einzelner Server (Nodes) zur Verfügung stehen.
Damit die Daten wieder gefunden werden, werden die Meta-Daten (wo liegt was) auf sogenannten Mastern gespeichert. Diese sind meistens auch Redundant aufgebaut. Die Nodes informieren die Master auch über eine heart-beat message das sie noch erreichbar und funktional sind.
Vertikale Skalierung
Bei der vertikalen Skalierung bekommt ein Server mehr Leistung (CPU, RAM, Speicher, …)
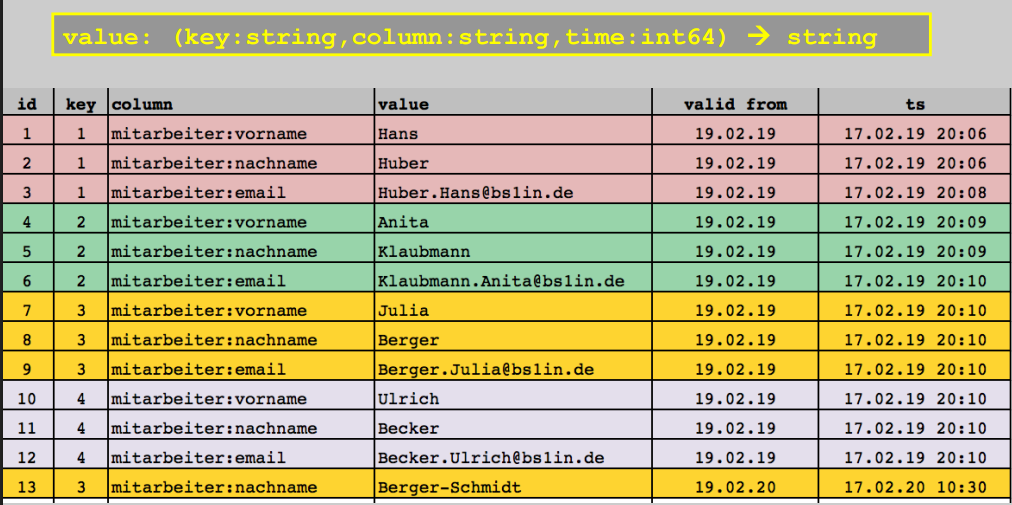
Big Table
- Datensätze werden oft hinzugefügt
- Existierende Datensätze werden selten geändert
- Verlauf der Datenänderungen ist ersichtlich
- horizontal skalierbar
Map-Reduce-Algorithmen
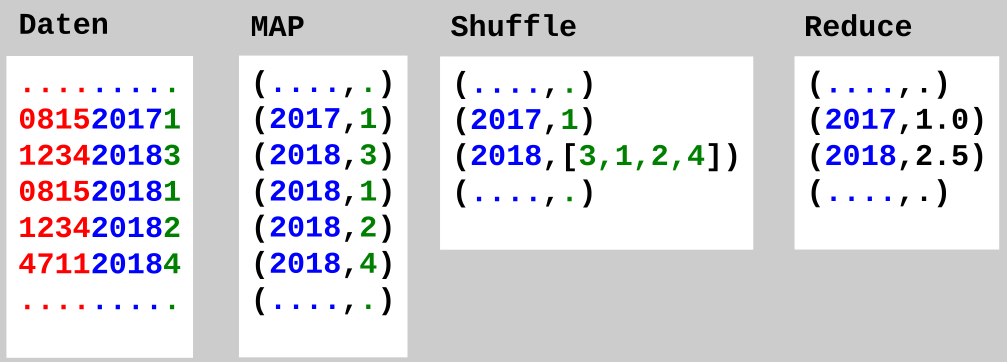
Da die Daten bei Big Data häufig über mehrere Systeme verteilt sind, müssen die Daten irgendwie sortiert werden. Dafür gibt es Map-Reduce-Algorithmen.
- Alle Daten liegen durcheinander auf verschiedenen Systemen
- Die Daten werden auf dem System wo sie aktuell liegen nach Typen sortiert
- Anschließend werden die gleichen Typen von allen Systemen zusammen gezogen. (Passiert NICHT im Cluster sondern in der Applikation, also logisch)
- Die Überflüssigen Daten werden Entfernt
Verarbeitung
Damit man große Mengen an Daten verarbeiten kann gibt es verschiedene Systeme.
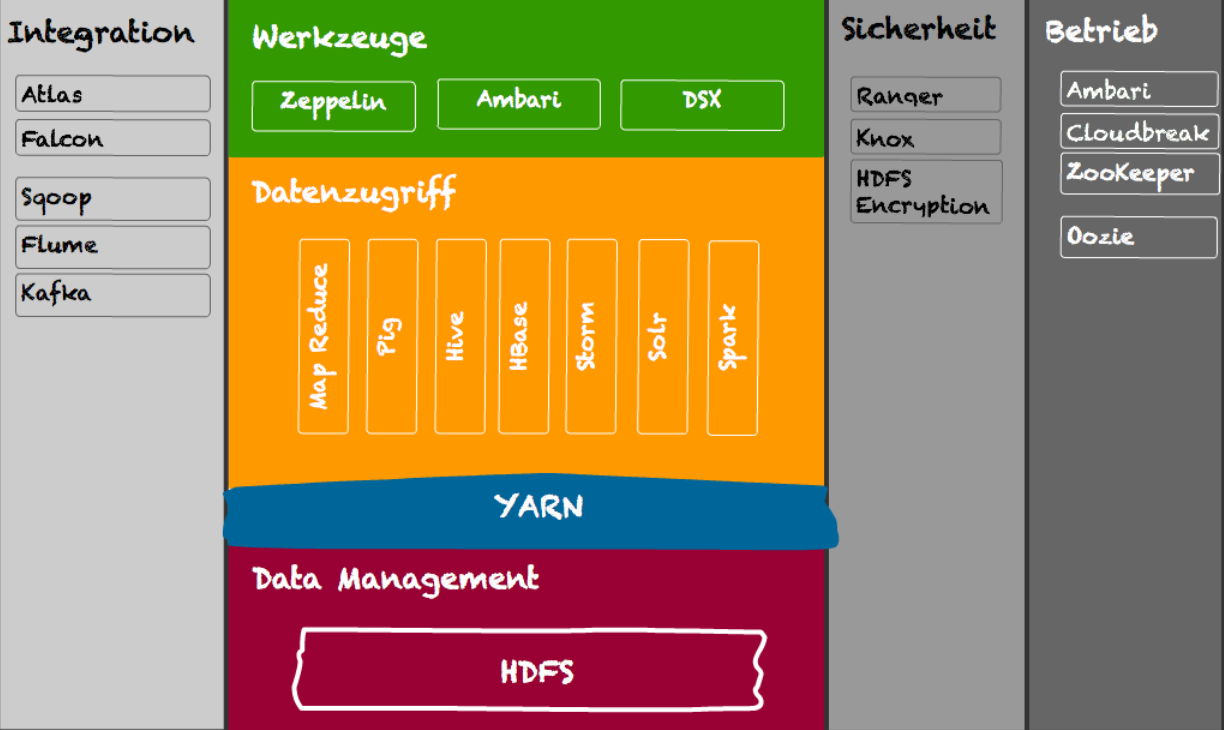
Hadoop
Wenn keine Echtzeit-Anforderung bei der Verarbeitung benötigt wird, ist Hadoop eine mögliche Option:
Lambda-Architektur
Ist eine Echtzeit-Anforderung bei der Verarbeitung gegeben empfiehlt sich eher die Lambda-Architektur bestehend aus folgenden Komponenten:
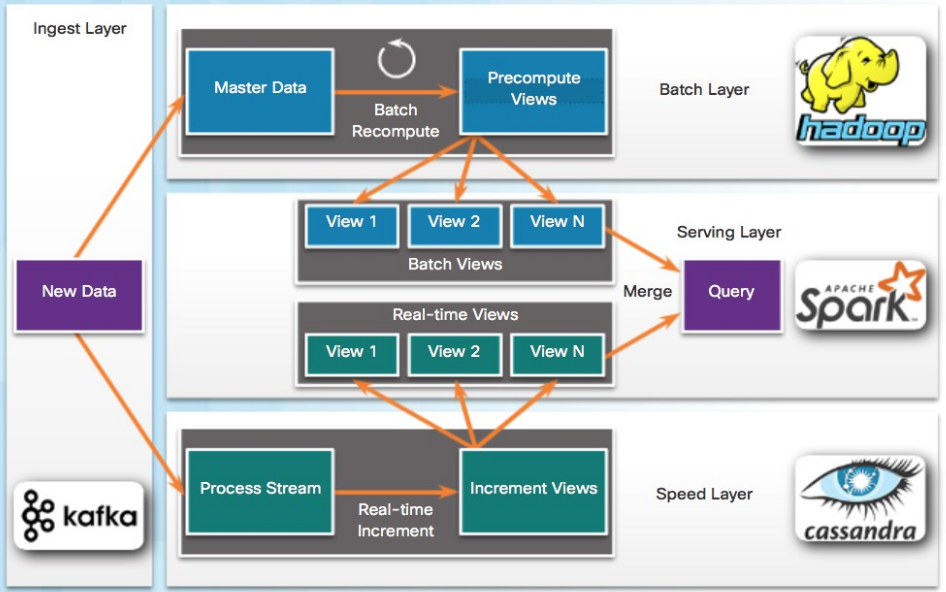
- Ingest Layer: neue Daten kommen hier rein und werden weiter geleitet an Batch und Speed Layer
- Batch Layer: Die historischen Daten werden hier verarbeitet. (langsam, aber vollständig)
- Speed Layer: Verarbeitung der neuen Daten (Echtzeit)
- Serving Layer: Führt die neuen und historischen Daten zusammen und stellt sie dar (beantwortet Querys)