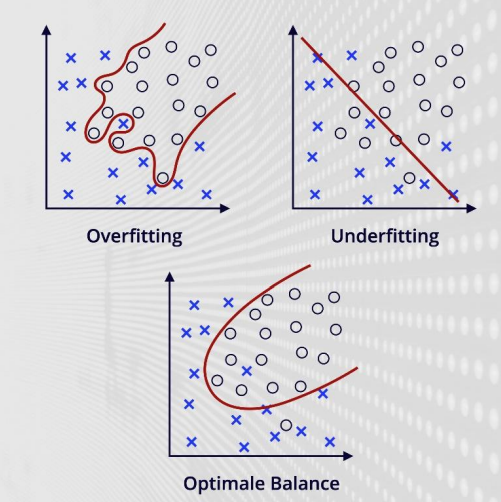
Over- and Underfitting
Confusion Matrix
Eine Tabelle die anzeigt wie die Daten klassifiziert wurden und wie es richtig gewesen wäre
Beispiel:

Import
from sklearn.metrics import confusion_matrixErstellen
confusion_matrix(
y_true: ArrayLike,
y_pred: ArrayLike,
*,
labels: ArrayLike | None = None,
sample_weight: ArrayLike | None = None,
normalize: Literal['true', 'pred', 'all'] | None = None
)Parameter
| Parameter | Bedeutung | Mögliche Werte |
|---|---|---|
y_true | Korrekte Klassen | Array |
y_pred | Von dem Modell vorhergesagte Klassen | Array |
labels | Angabe der Reihenfolge der Klassen | Array / None |
sample_weight | Array / None | |
normalize | Normalisiert die Ergebnisse über die Wahre ("true"), vorhergesagte ("pred") oder alle ("all") Werte | "true" / "pred" / "all" / None |
| Beispiel: |
# y Hier berechnen
confusion_matrix = confusion_matrix(y_test, clf.predict(x_test))
# y Bereits berechnet
cm = confusion_matrix(y_test, y_pred)Visualisierung
from sklearn.metrics import ConfusionMatrixDisplay
ConfusionMatrixDisplay(confusion_matrix=confusion_matrix).plot()Accuracy
Allgemein wird oft „Accuracy“ also „Genauigkeit“ als grundlegender Wert für die Treffsicherheit genannt. Jedoch erweist sich dieser Wert in vielen Anwendungsszenarien als trügerisch und manchmal als völlig sinn frei.
Er wird definiert mit: Umso höher der Wert (Maximum ist 1), umso genauer, akkurater ist unser Classifier.
# Import des Accuracy Score
from sklearn.metrics import accuracy_score
# Erstellen der Accuracy
accuracy_score(y_true, y_pred, normalize=True, sample_weight=None) | Parameter | Bedeutung | Mögliche Werte |
|---|---|---|
y_true | Korrekte Klassen | Array |
y_pred | Von dem Modell vorhergesagte Klassen | Array |
normalize | False: gibt die Nummer der Korrekt Klassifizierten zurück True: Gibt den Anteil der korrekt Klassifizierten zurück | True / False |
sample_weight | Array / None |
Precision
Precision erlaubt eine Einordnung der Genauigkeit in Hinblick auf falsch positive Ergebnisse eines Classifiers. Falsch negative Ergebnisse bleiben außen vor. Der Wertebereich sollte ebenfalls nahe bei „1“ oder 100% liegen.
# Importieren des Precision Score
from sklearn.metrics import precision_score
# Erstellen der Precision
precision_score(y_true, y_pred, labels=None, pos_label=1, average='binary', sample_weight=None, zero_division='warn')| Parameter | Bedeutung | Mögliche Werte |
|---|---|---|
y_true | Korrekte Klassen | Array |
y_pred | Von dem Modell vorhergesagte Klassen | Array |
labels | Reihenfolge der Klassen | Array / None |
pos_Label | Die Klasse die verwendet werden soll | float |
sample_weight | Array / None |
Recall
Der Recall-Score erlaubt die Einordnung der Ergebnisse in Hinblick auf die Rate von falsch negativen Klassifikationen eines Classifiers. Er ist der Gegenspieler der Precision. Der Werte Bereich sollte ebenfalls nahe bei „1“ oder 100% liegen.
# Importieren des Recall Score
from sklearn.metrics import recall_score
# Erstellen der Recall
recall_score(y_true, y_pred, labels=None, pos_label=1, average='binary', sample_weight=None, zero_division='warn')| Parameter | Bedeutung | Mögliche Werte |
|---|---|---|
y_true | Korrekte Klassen | Array |
y_pred | Von dem Modell vorhergesagte Klassen | Array |
labels | Reihenfolge der Klassen | Array / None |
pos_Label | Die Klasse die verwendet werden soll | float |
sample_weight | Array / None |
F1 Score
Der F1-Score erlaubt eine Einschätzung bezüglich der allgemeinen Genauigkeit eines Classifiers. Er verbindet dabei die Ergebnisse der Precision und des Recall.
# Importieren des F1-Score
from sklearn.metrics import f1_score
# Erstellen der Recall
f1_score(y_true, y_pred, labels=None, pos_label=1, average='binary', sample_weight=None, zero_division='warn')| Parameter | Bedeutung | Mögliche Werte |
|---|---|---|
y_true | Korrekte Klassen | Array |
y_pred | Von dem Modell vorhergesagte Klassen | Array |
labels | Reihenfolge der Klassen | Array / None |
pos_Label | Die Klasse die verwendet werden soll | float |
sample_weight | Array / None |